Part I: TRUE OR FALSE
Storage and file systems
1. The peak read bandwidth of a RAID-4 array grows linearly with the number of disks, but the single parity disk limits the peak write bandwidth.
2. Doubling the rotation speed of a 10K RPM (rotations per minute) disk doubles its peak transfer bandwidth, but improves its throughput for random 8KB reads only marginally.
3. Doubling the bit density of a 10K RPM disk doubles its peak transfer bandwidth, but improves its throughput for random 8KB reads only marginally.
4. You have a system with two primary workloads. One performs sequential access to a set of large files; the other performs small, independent, random reads to a separate set of large files. To satisfy these two workloads, you have a set of 4 disks. Both applications can saturate the peak bandwidth of your disk subsystem (i.e., they are I/O bound). Each disk can provide 100MB/s and has an average seek time of 10ms. The best way to organize data on these disks in order to provide the best performance for the random workload is to mirror the disks (that is, store 4 identical replicas on the 4 disks).
5. A log-based file system can deliver data at close to the peak transfer bandwidth of its disk system, independent of which files or directories are being accessed.
6. A log-based file system can perform writes and updates at close to the peak transfer bandwidth of its disk system, independent of which files or directories are being updated.
7. To preserve data integrity, file system software must control the order in which disk writes complete.
8. Swap space allocated as a special region (partition) on the disk can be faster than if allocated as a special file because it avoids file system costs due to disk organization.
9. A stateful file service recovers faster after a crash because all state information is stored locally, while a stateless file service needs to bring state information from a distant node.
10. AFS/Ceph (answer for the one you read) provides a stateful file service.
Distributed coordination
11. The centralized approach to deadlock detection in a distributed system requires a larger number of messages than a decentralized approach (which is the reason why decentralized solutions are always preferred).
12. An election algorithm for a bidirectional ring can be more efficient than the one presented in the textbook for the unidirectional ring.
13. A deadlock detection scheme is always more efficient than a deadlock prevention scheme in distributed systems.
14. Events in a distributed system can be globally ordered in time using the happened-before relationship presented in Lamport’s paper.
15. In a distributed system deployed over the Internet, agreement among n processes can be reached always in constant x (n+1) rounds of communication.
Part II: ELABORATE
16. You have a system with two primary workloads. One performs sequential access to a set of large files; the other performs small, independent, random reads to a separate set of large files. To satisfy these two workloads, you have a set of 8 disks. Both applications can saturate the peak bandwidth of your disk subsystem (i.e., they are I/O bound). Each disk can provide 100MB/s and has an average seek time of 10ms.
a. How should you organize these disks and lay out your data to provide best performance for the sequential workload?
b. How should you organize these disks and lay out your data to provide best performance for the random workload?
c. If you want to run both applications simultaneously and achieve the maximum average bandwidth for each application, how should you organize these disks and data?
d. Suppose the random reads are dependent, in that each request cannot be submitted before the previous one completes. Does this change the answer to question c)? If so, how?
17. Distributed file systems:
e. Most distributed file systems cache recently used file data in client memory. What are the performance benefits of file caching? What are the performance costs?
f. File caching introduces the problem of cache consistency when files are shared across the network.
Explain the problem and demonstrate it with an example.
g. Outline a plausible scheme for dealing with the problem of cache consistency in a distributed file system. You may ignore the problem of failures in your answer (but see next question). Your scheme need not be identical to that used in any specific distributed file system.
h. What are the limitations of the file caching scheme you described for previous question? Explain how your scheme can handle failures (crashes), assuming that systems fail only by stopping, discarding the contents of their memory, and restarting.
18. Problem 18.8 Silberschatz.
19. Clocks in distributed systems:
a. Why are clocks difficult to synchronize in distributed systems?
b. What features in a system assume that the clocks are (reasonably) synchronized? Give two examples of cases where a problem would occur if the clocks were not synchronized.
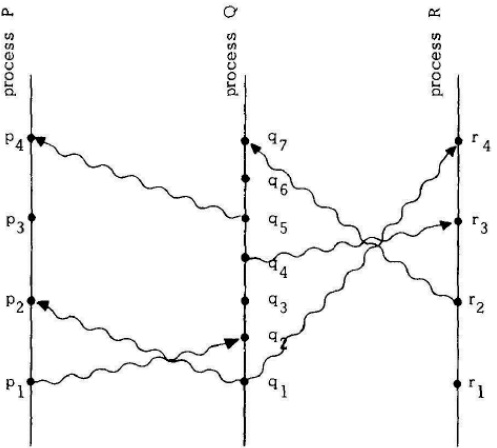
c. Order the following events based on the figure below according to the happened before relationship as introduced by Lamport. Consider that the vertical lines represent events in a process ordered chronologically from bottom up (that is, time grows going up on the axis).
- p3, q3, q5, r3
- r1, q4, r4
- p1, q3, r3, r4
20. Consider a setting where processors are not associated with unique identifiers but the total number of processors is known and the processors are organized along a bidirectional ring. Is it possible to derive an election algorithm for such a setting?