Q1. If two binary random variables X and Y are independent, are X‾ (the complement of X) and also independent? Prove your claim.
Q2. To estimate the head probability θ of a coin from the results of N flips, we use fictional observations (or pseudo-counts) to incorporate our belief of the fairness of the coin. This is equivalent to using which distribution as a prior of θ?
Q3. Suppose we have two sensors with known (and different) variances v1 and v2, but unknown (and the same) mean μ. Suppose we observe N1 observations yi(1) ˜ N(μ, v1) from the sensor and N2 obersvation yi(2) ˜ N(μ, v2) from the second sensor.
Let D represent all the data from both sensors. What is the posterior p(μ|D) assuming a non-informative prior for μ (which we can simulate using a Gaussian with a precision of 0)?
Q4. Consider K nearest neighbors (K-NN) using Euclidean distance on the following 10 data points (each point belongs to one of two classes: + and o)
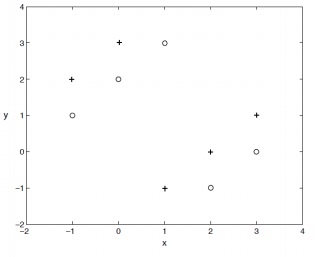
What is the leave-one-out cross-validation error when K=1?
Let K= 3, 5, and 9, which values of K leads to the minimum number of validation error? What is the error for that K?
Q5. For linear regression, when the input x is scalar, so d=1, show that the ML estimation is given by the following equations.
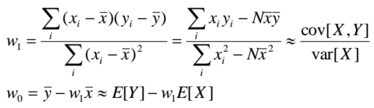
Q6. Let p(y|x,w) be a logistic regression model. Show that the log-odds of success (or the logit) of the probability defined as
ln [p(y=1|x,w)/p(y=0|x,w)]
Is a linear function of x.
Q7. For each of the following pairs of directed probabilistic graphical models in the following figure, determine of the two graphs are equivalent (e.g., they have the same set of independence assumptions).
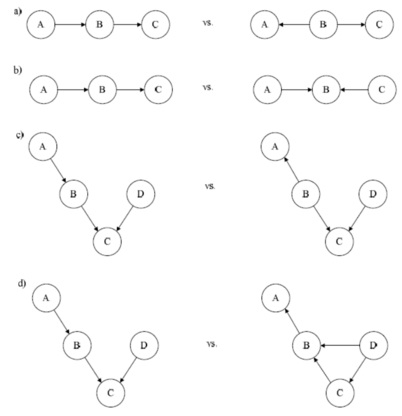
When they are equivalent, state ONE (conditional) independence assumption shared by them
When they are not equivalent, state ONE (conditional) independence assumption satisfied by one but not the other.
Q8. The Gaussian mixture model (GMM) and the K-means algorithm are closely related (the latter is a special case of GMM). The likelihood of a GMM with denoting the latent variable can be expressed as
p(x) = Σz p(x | z) p(z)
where p(x|z) is the (multivariate) Gaussian likelihood conditioned on the mixture component, and p(z) is the prior on the components. Such a likelihood formulation can also be used to describe a K-means clustering. Which of the following statements are true?
a. p(z) is uniform in K-means but this is not necessarily true in GMM
b. The values in the covariance matrix in p(x | z) tend towards zero in K-means but this is not so in GMM
c. The covariance matrix in p(x | z) in K-means is diagonal but this is not necessarily the case in GMM