DATA MINING and NEURAL NETWORKS
Computational Task 1
Please consider the following database.
It represents some of the results of presidential elections in the USA over the period from 1860 until 1992.
For your convenience data were separated in 2 classes: p–class corresponds to the elections when the presidential party (P-party) candidate won, o–class means opposition candidate (O-party) won.
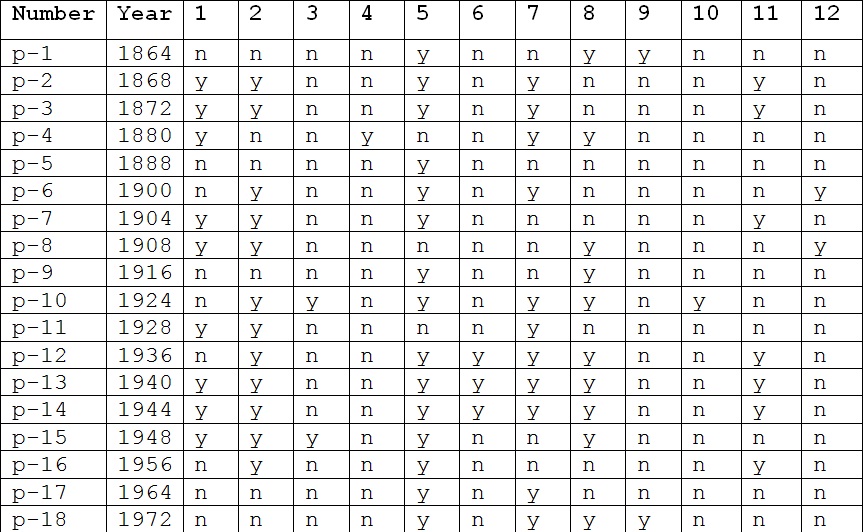
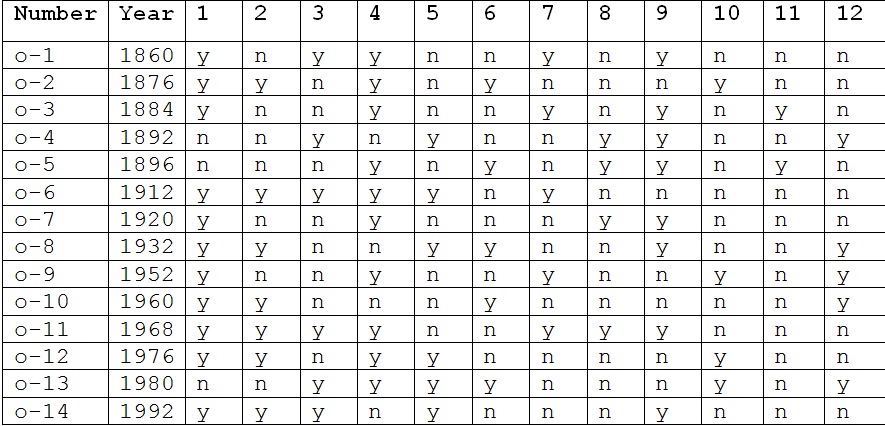
Attributes were filled according to the answers to the 12 questions.
Questions:
1) Has the P-party been in power for more than one term?
2) Did the P-party receive more than 50% of the popular vote in the last election?
3) Was there important activity of a third party during the election year?
4) Was there serious competition in the P-party primaries?
5) Was the P-party candidate the president at the time of election?
6) Was there a depression or recession in election year?
7) Was there a growth in the gross national product of more than 2.1% in the year of election?
8) Did the P-party president make any substantial political changes throughout his term?
9) Did significant social tension exist during the term of the P-party?
10) Was the P-party administration guilty of any serious mistakes or scandals?
11) Was the P-party candidate a national hero?
12) Was the O-party candidate a national hero?
P-PARTY VICTORIES
Election Answers to Questions
O-PARTY VICTORIES
The task is:
1) Convert the table into format convenient for the processing with MATLAB.
2) Prepare program that perform K Nearest Neighbours algorithm using Euclidian distance. (Your program should not utilise the MATLAB function for KNN)
3) For each row (instance) from the table prepare the results of the cross-validation: for each instance apply the program for different values of K = 1, 2,3,4,5. Analyse the accuracy of the classification using cross-validation and visualize your results.
4) Please create a decision tree for prediction of USA presidential elections. Choose randomly several example of each class for the test set and exclude them from the training set. Find the training and the test set errors.
5) Which technique works better for this dataset? Elucidate please.
6) Please write a conclusion.